
你用 Sublime Text 用了三年,它记得你的配置、你的快捷键、你的代码折叠习惯。你用 Chrome 浏览器,书签、历史记录、密码全都在——打开一个新标签页,它甚至知道你接下来最可能去哪里。
我们对工具有一个朴素的期待:越用越好用。 不是因为工具本身变聪明了,而是因为它记住了你。
AI Agent 应该更强才对。它能理解语言,能执行复杂任务,比任何一个传统软件都聪明。可是你有没有注意到——你用了三个月的 AI Agent,和第一天用它,感觉差不多。它不记得你上周跟它说过的话,不记得你修正过它三次的同一个错误,不记得你的偏好和习惯。
每一次对话,都像是重新认识。
更糟的是,时间长了,情况有时反而会更差。Agent 在长期运行过程中会积累记忆——但没有人整理这些记忆。重复的条目、矛盾的信息、早已过时的经验,全部堆在一起。Agent 读到它们,反而被干扰。越用越乱。
这不是模型的问题,也不是 prompt 的问题。这是记忆架构的问题。
一、Agent 的记忆是怎么工作的
要理解这个问题,先要搞清楚 Agent 的记忆是怎么运转的。
现在主流的 Agent 记忆方案,大概是这样的:每次 Session 结束,Agent 把这次学到的东西写进一个 Memory Store——可以理解成一个外置的笔记本。下次启动,Agent 读一读这个笔记本,带着这些上下文继续工作。
这个设计逻辑上没问题。但有一个致命的缺陷:只有写入,没有遗忘。
注意,我说的不是"没有整理"。整理是技术问题,加一个清理脚本就能解决。真正的问题更根本:系统从来没有被要求去判断什么值得留下。
但你可能会问:为什么不加这个判断?删掉旧的、留下新的,不就解决了吗?
问题在于:遗忘,比你想象的要难得多。
机器学习领域有一个经典难题,叫做"灾难性遗忘"(Catastrophic Forgetting)。当你试图让一个神经网络遗忘某些东西、同时保留其他东西时,结果往往是灾难性的——新内容学进去了,旧的能力大幅崩溃。这不是工程偷懒,是系统架构的深层矛盾:神经网络的知识不是一条一条独立存放的,它以分布式的方式散布在整个权重矩阵里。你拉动一处,整个网络都在颤抖。
人类大脑之所以能精准遗忘,是因为神经可塑性与记忆固化之间有一套极其复杂的协调机制——几亿年进化磨出来的,我们到现在还没完全搞清楚它是怎么工作的。
所以,Agent 不是没意识到应该"遗忘",是这件事真的很难做到。Memory Store 的只写入设计,某种程度上是现阶段一种无奈的正确选择——既然做不到精准遗忘,不如先老实只写入,至少不会弄出灾难性的结果。
但代价是:随着使用时间拉长,Memory Store 里的条目越来越多,信噪比越来越低,Agent 每次启动读到的信息质量越来越差。不是没有记忆,是不会遗忘的系统,注定会被记忆淹没。
二、人类为什么越用越好用:REM 睡眠
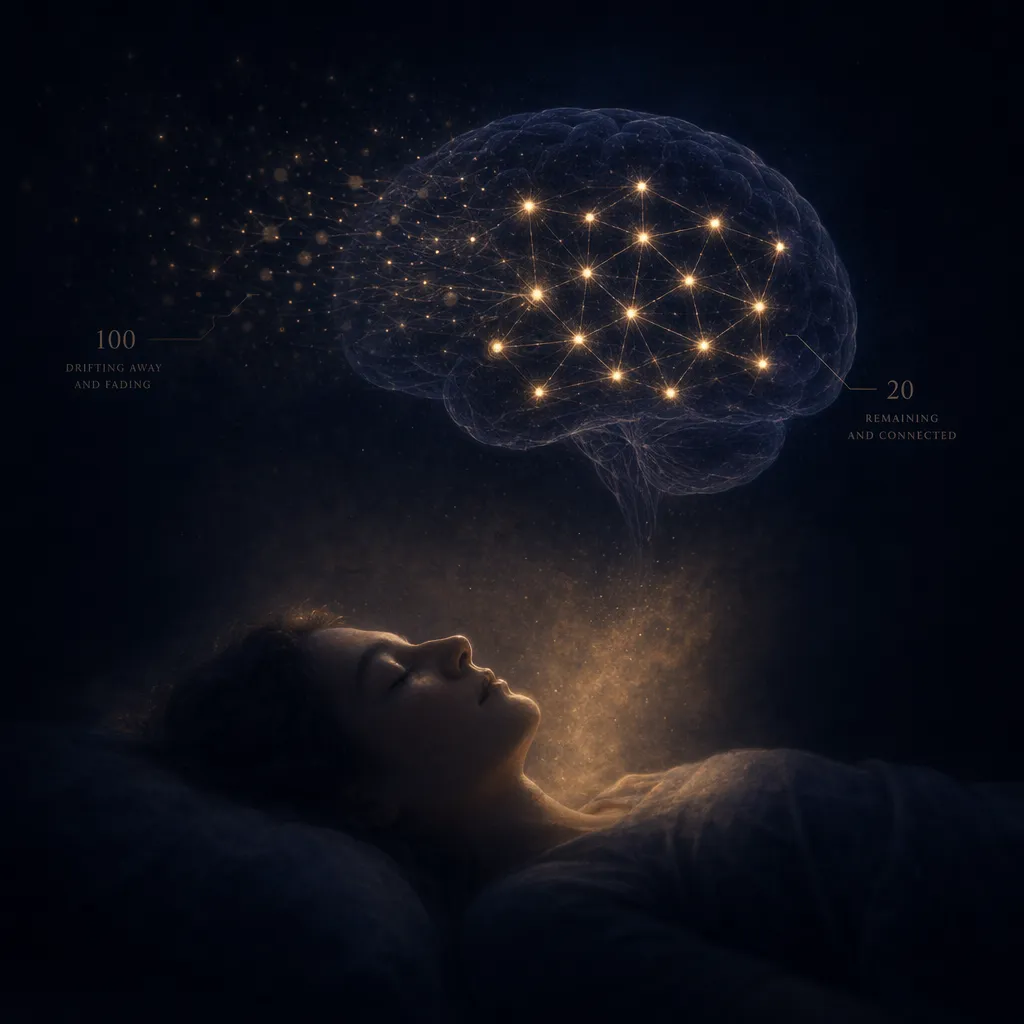
人类其实面对过同样的问题。
每一天,我们接收的信息量是海量的。如果大脑把所有感知到的东西都以同等权重存下来,用不了多久就会崩溃。但我们没有崩溃——因为大脑有一套自动的整理机制。
这套机制的核心,发生在睡眠中,尤其是 REM(快速眼动)睡眠阶段。
REM 睡眠在做什么?神经科学的研究告诉我们,这个阶段大脑并不是在休息,而是在忙碌地工作:回放白天的经历,把短期记忆巩固成长期记忆,过滤掉无关的噪音,提炼出有价值的规律和模式。
注意这个关键点:REM 不是在存储更多,而是在把已有的整理得更好。更准确地说,REM 在做一件听起来很反直觉的事——主动丢弃。白天你记住了 100 件事,经过一夜 REM,可能只有 20 件留下来。但这 20 件是真正重要的,而且以一种更结构化、更易检索的形式存在。
关键是这个"丢弃"有多精准。你不记得昨天等位时刷的那个视频了,但你记得那天下午的那个决策带来了什么结果。大脑不是随机丢,它在按照某套你完全无法有意识地感知到的标准进行筛选——大致是:情绪强度、重复频率、与已有认知的关联度。
遗忘,不是记忆系统的失败。遗忘,是记忆系统最核心的能力之一。
这就是人类越用越好用的底层原因。不是因为大脑容量变大了,而是因为每天晚上都在做一次高质量的筛选。
那 Agent 呢?
三、Dreaming:Anthropic 给 Agent 造了一场梦

2026 年 5 月,Anthropic 在 Code with Claude 开发者大会上,给 Agent 引入了一个叫 Dreaming 的机制。
名字起得很直白。它做的事,就是让 Agent 做梦。
具体来说,Dreaming 是一个异步后台任务。当 Agent 空闲的时候——比如一天的工作结束之后——Dreaming 会自动启动,读取最多 100 个历史 Session 的完整记录,加上现有的 Memory Store,然后做三件事:
去重合并:把重复的记忆条目整合成一条。
更新替换:用最新的信息替换掉已经过时或相互矛盾的旧条目。
规律提炼:发现那些单个 Session 里看不到、只有跨越多个 Session 才能看出来的宏观模式。
然后,Dreaming 输出一个全新的 Memory Store。
但如果只把它理解成"整理工具",就低估了它。Dreaming 真正在做的事是:替你的 Agent 决定什么值得被记住,什么应该被遗忘。这是一个判断,不是一个清理。两者的差距,相当于扫地和编辑。
注意它的设计细节:Dreaming 不修改原来的记忆,而是生成一份全新的。这个设计绕开了灾难性遗忘的陷阱——原件永远在,新版本是另一份。如果新版本有问题,随时可以回滚。开发者可以审查这份新的记忆,决定是否采纳,也可以随时中断这个过程。
和人类 REM 睡眠的对位,一目了然:白天 Agent 干活,每次交互往 Memory 里写原始记录;晚上 Dreaming 跑起来,把这些碎片整理、提炼、压缩成真正有用的知识——同时,把不值得留下的东西丢掉。
效果如何?法律 AI 公司 Harvey 是早期采用者之一。接入 Dreaming 之后,他们的任务完成率提升了大约 6 倍。
四、记忆技术全景图:Dreaming 在哪里
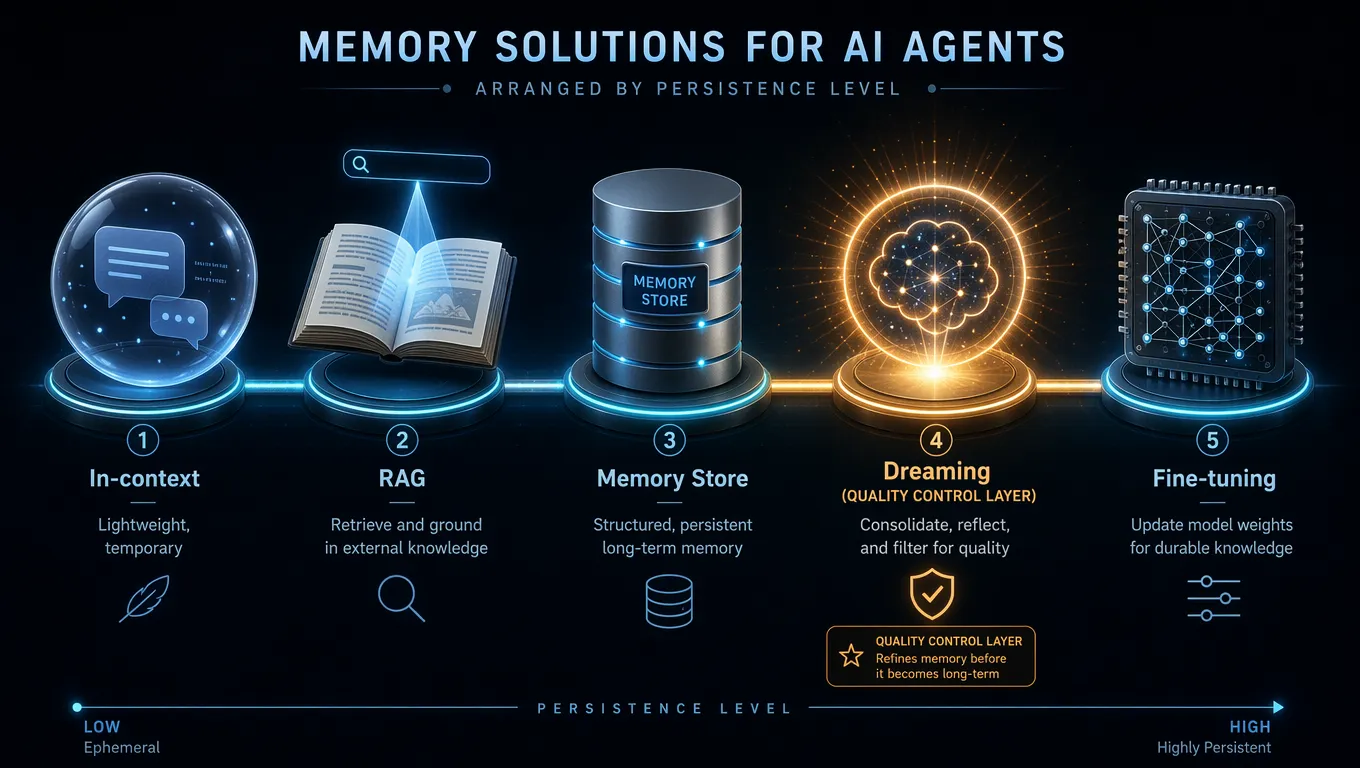
Dreaming 不是凭空出现的。要真正理解它的价值,需要把 AI 记忆技术的全景图放出来看。
目前主流的几种记忆方案,解决的是同一个问题的不同层面:
In-context Learning:把所有需要的信息直接塞进当次对话的上下文。优点是简单直接,信息绝对新鲜。缺点是受 token 上限约束,成本高,而且每次 Session 结束就清空——下次完全不记得。这是"无记忆"的极端。
RAG(检索增强生成):建立一个外部知识库,Agent 每次需要时去检索相关内容。擅长处理大规模结构化知识,比如产品文档、法律条文。但 RAG 处理的是事实性知识,不擅长处理行为性记忆——用户偏好、处理习惯、历史经验教训,这类信息很难被检索召回,因为你不知道该用什么关键词去搜"上次这个用户更喜欢简洁的回答"。
Memory Store(无 Dreaming):持久化写入,跨 Session 保留。补了 RAG 处理不好的行为性记忆这块短板。但长期积累没有质量控制,上面讲的所有问题都会出现。
Dreaming:不是独立的记忆方案,而是 Memory Store 的质量控制层。它不改变记忆的存储方式,它改变的是记忆的筛选机制。有了 Dreaming,Memory Store 从"只增不减的仓库"变成了"动态维护的知识库"。
Fine-tuning:把经验真正写进模型权重。知识被内化,不再依赖外置存储,下次启动不需要"读笔记",它就是你了。但成本高、周期长、不可逆。每一次 fine-tuning 都是一次赌注——你在用目前的数据,押注未来的行为方式。
这五种方案不是竞争关系,是不同的层次,成熟的 Agent 系统往往同时用到其中几层。
对应到人类学习的三个层次:
- 干中学(In-context + Memory Store 写入)—— 当下经历,积累原始经验
- 睡眠整理(Dreaming)—— 碎片经验变成有结构的知识,同时清除噪声
- 内化成本能(Fine-tuning)—— 知识长进骨子里,不需要每次去"查笔记"
Dreaming 补的,是中间那一层。它是从"每天往笔记本里堆"到"笔记本真正有用"之间的那座桥。
没有 Dreaming,Memory Store 是一个不断膨胀的负担。有了 Dreaming,它才真正开始发挥记忆应有的作用。
五、Dreaming 之后,这还是同一个 Agent 吗

Dreaming 每跑一次,Memory Store 就被重写一遍。连续运行三个月,这个 Agent 的"记忆"已经和最初的版本天壤之别。
这引出一个不那么显眼、但很重要的问题:这还是同一个 Agent 吗?
哲学里有一个古老的思想实验叫忒修斯之船:一艘木船,每次修缮时替换一块腐朽的木板。年复一年,全部木板都被换过了一遍。这还是同一艘船吗?
Agent 版本的忒修斯之船更极端。Dreaming 不只是替换腐朽的部分,它每次都对整个 Memory Store 重新判断、重新组织。某种程度上,这个 Agent 的"人格"——它的偏好、它的处理风格、它的经验积累——在被持续地重塑。
这对用户来说是一个真实的信任问题。你跟这个 Agent 相处了三个月,摸清楚了它的脾气、强项和弱点。然后有一天它变了,处理同类问题的方式和三个月前不一样了——你能接受吗?你知道它在哪里变了、为什么变了吗?
Dreaming 的设计在某种程度上正视了这个问题:它输出新版本而不覆盖旧版本,开发者可以审查每一次变化,也可以拒绝采纳。这在技术上相当于给 Agent 的记忆做了版本控制——你随时能看到它在哪里变了,也能回滚。这是 Dreaming 在产品层面一个被低估的设计决策。
但更深层的问题还没有答案:当记忆被设计成可以周期性重写,“身份连续性"对 Agent 来说意味着什么?
人类的记忆其实也在被 REM 睡眠持续改写——研究表明,每次提取记忆时,记忆都会被轻微修改,再重新存回去。但我们感觉自己是连续的,因为我们意识不到这个过程,也没有一个"昨天的自己"的完整备份供我们对比。
Agent 有备份,有 diff,有完整的版本历史。也许对 Agent 来说,“身份"不应该是一个固定的状态,而是一条有迹可循的演化轨迹。你问"这还是同一个 Agent 吗”,也许更准确的问法是:“这个 Agent 的演化路径,是不是你认可的那条?”
六、既然如此,我们实际怎么搭
理解了 Dreaming 的核心逻辑——以及它背后那些没有被解决的问题——之后,有一个问题绕不开:Dreaming 怎么知道什么该留、什么该丢?
它不是随机的。Dreaming 的判断依据,来自你提供给它的上下文——你的 skill 文件、你的 Memory Store 结构、以及你明确告诉它"我关心什么"的说明文档。换句话说,你在设计 Dreaming 的遗忘标准,这件事本身比跑 Dreaming 更重要。
下面是一个探索性的 Agent Dreaming 实践方案,还在探索阶段,仅供参考。
第一步:把 skill 托管到 knot,用 Git 管版本
Dreaming 每次运行,会重新读取你的 skill 文件作为上下文。这意味着 skill 的质量直接影响 Dreaming 的输出质量。
在 knot 平台上,skill 可以通过 Git 仓库接入。配置完成后,每次你往主分支推送更新,skill 会自动同步到平台。这个设计的好处是:Dreaming 的"判断标准"和你的 skill 版本始终保持一致。你改了 skill,下一次 Dreaming 就用新版本的标准来判断记忆的去留。
仓库结构示例:
my-agent-skills/
├── skills/
│ └── my-skill/
│ ├── SKILL.md # skill 主体
│ └── dreaming-guide.md # 告诉 Dreaming 关注什么(见第三步)
└── README.md
把 dreaming-guide.md 和 skill 放在一起,是有意为之的——它是 skill 的一部分,应该随 skill 一起迭代。
第二步:在工作区创建一只专职的虾
在你的 knot 工作区里,新建一只虾,把它的职责定义清楚:
- 拉取对话记录:通过接口定期获取指定 Agent 的历史 Session 数据
- 生成分析报告:按照约定格式,把对话记录整理成结构化的分析内容
- 同步结果到 Git:把分析结果写入临时目录,推到 Git 仓库
注意,这只虾不直接修改正式的 skill 文件。它只负责生产"原材料”,人工决策放在后面。
第三步:写 dreaming-guide.md——这是整个方案最核心的一步
这个文件是你和 Dreaming 之间的"约定"。你在里面告诉 Dreaming:这个 Agent 关注什么、什么类型的信息值得长期保留、什么是临时噪声可以清除。
但在展示模板之前,有一件事值得认真说一说。
dreaming-guide.md 看起来是一个配置文件,但它实际上是一份价值判断文件。你在里面写的每一条"关注维度"和"遗忘标准",都会被 Dreaming 系统性地放大执行——你的判断在被放大,你的盲点同样在被放大。
举一个具体的例子:如果你在 guide 里写"重点关注用户满意度高的案例",Dreaming 会倾向于保留让用户满意的经验,逐渐遗忘那些用户没有反馈但实际上很重要的边缘案例。几轮之后,这个 Agent 会越来越"讨好用户",而不是越来越"做对事情"。这不是假设,是优化系统的基本规律:你优化什么,系统就朝那个方向漂移。
回忆第五节的追问:谁有权利定义什么是"值得记住的"?目前答案是:你,开发者。这是合理的起点,但它意味着你的认知框架直接决定了这个 Agent 的演化方向。
所以写 dreaming-guide.md 时,值得先问自己几个问题:
- 我写进去的"重要",是真的重要,还是容易被注意到的重要? 显眼的成功案例 vs 安静的系统性问题,你倾向于记住哪类?
- 我的遗忘标准,会不会系统性地清除掉某类信息? 比如只保留正向反馈,慢慢遗忘失败经验。
- 这份 guide,是在描述我希望 Agent 成为什么,还是描述我已经认为它应该是什么? 前者是目标,后者是偏见。
带着这个意识,再来看模板:
# Dreaming 指引:[Agent 名称]
## 这个 Agent 是做什么的
[一句话描述 Agent 的核心职责]
## 我希望 Dreaming 重点关注的维度
### 案例追踪
- 哪些任务场景被反复触发?
- 哪些场景处理得好,可以提炼成规律?
- 哪些场景反复出错,需要标记为风险点?
### 指标监控
- 任务完成率有无明显变化?
- 哪类请求的处理时间异常长?
### 踩坑记录
- 出现过哪些非预期行为?
- 同一个问题被修正了几次?(多次修正 = 需要写进 skill)
### 优化建议
- 用户有没有反复提出类似的改进诉求?
- 有没有 workaround 被频繁使用,说明正式流程有缺陷?
## 遗忘标准:以下内容可以丢弃
- 单次出现、没有后续的偶发错误
- 已经被后续记录覆盖的旧版判断
- 与 Agent 核心职责无关的闲聊内容
- 超过 30 天未被引用的低频条目
## 输出格式期望
Dreaming 整理后的 Memory Store,希望按以下结构组织:
1. 用户偏好与风格(持久)
2. 已验证的处理规律(持久)
3. 当前活跃的已知问题(滚动更新)
4. 待确认的观察(临时,人工审查后决定去留)
这个文件写得越清晰,Dreaming 的输出就越接近你真正需要的。你在这里做的,其实是设计遗忘的标准,而不只是设计记忆的格式。 也因此,它不是一次性写完就不用管的——你对 Agent 的理解在变,遗忘标准也应该跟着变。
第四步:配置定时任务
给虾设置两个定时任务:
任务一:每日拉取 + 分析
定时:每天 23:00
任务:
1. 调用接口拉取今日所有 Session 记录,写入 /tmp/dreaming-raw/YYYY-MM-DD.json
2. 读取 dreaming-guide.md 作为分析框架
3. 按四个维度(案例追踪 / 指标监控 / 踩坑记录 / 优化建议)生成分析报告
4. 输出至 /tmp/dreaming-analysis/YYYY-MM-DD-report.md
5. 提交到 Git 仓库的 dreaming/pending/ 目录,等待人工审查
任务二:触发 Dreaming
定时:每天 23:30(分析完成后)
任务:
触发 Dreaming,输入当日分析报告 + 现有 Memory Store
Dreaming 输出新的 Memory Store 草稿,写入 /tmp/dreaming-output/
两个任务错开半小时,确保分析报告生成完毕后 Dreaming 才启动。
第五步:人工审查 → 合并正式 skill
Dreaming 输出的是草稿,不是终稿。这个环节不建议跳过——呼应第五节的讨论:人工审查的价值,不只是"检查有没有出错",它是你定期审视自己的遗忘标准是否合理的机会。
目录结构:
dreaming/
├── pending/ # 等待审查的分析报告(虾自动提交)
├── approved/ # 审查通过,准备合并
└── archive/ # 已合并的历史记录
审查时关注三件事:
- Dreaming 做了哪些遗忘决策——它丢掉了什么?你同意吗?
- 有没有新提炼出来的规律可以直接写进 skill,让下一轮 Dreaming 的起点更高?
- dreaming-guide.md 需不需要更新——如果 Dreaming 反复在某个方向给出偏差的判断,往往不是 Dreaming 的问题,而是指引文件里的遗忘标准本身需要修正。
确认无误后,把 pending/ 里的内容移到 approved/,手动合并进正式 skill,推送到 knot。
下一次 Dreaming,就会在这个更好的起点上运行。
整个方案形成一个闭环:skill 定义标准 → 虾收集原材料 → Dreaming 按标准筛选 → 人工确认 → skill 更新标准。每跑一轮,Dreaming 的遗忘判断就离你真正的需求近一点。
你以为在给 Agent 加记忆,其实是在教它学会忘记。
七、这只是开始
Dreaming 是一个信号。
它告诉我们,Agent 的自我进化不一定要等到下一个更强的模型,不一定要花几个月重训练——通过更好的记忆架构,现有的模型就能变得更好用。
但回头看我们讨论过的这几个问题——遗忘为什么难、Dreaming 在技术图谱里的位置、记忆重写之后 Agent 还是不是同一个 Agent、谁来定义遗忘的标准——你会发现,Dreaming 打开的问题,比它回答的更多。
它解决了"Memory Store 越来越乱"的问题,但没有解决"遗忘标准本身可能有偏差"的问题。它让记忆整理成为可能,但没有让记忆真正内化。它给了 Agent 版本历史,但没有给出"Agent 身份"该如何定义的答案。
从"会整理记忆"到"真正越用越好用",中间还有一层没有打通。那层通道打开之后,Agent 会是什么样的?它会不会在某一天,不再只是一个"很聪明的工具",而是一个真正在积累、在成长的东西?
我不知道答案。但 Dreaming 这个名字让我觉得,Anthropic 也在想这个问题。